Camadas e Profundidade: Onde nasce o "Deep Learning"
CURIOSIDADES
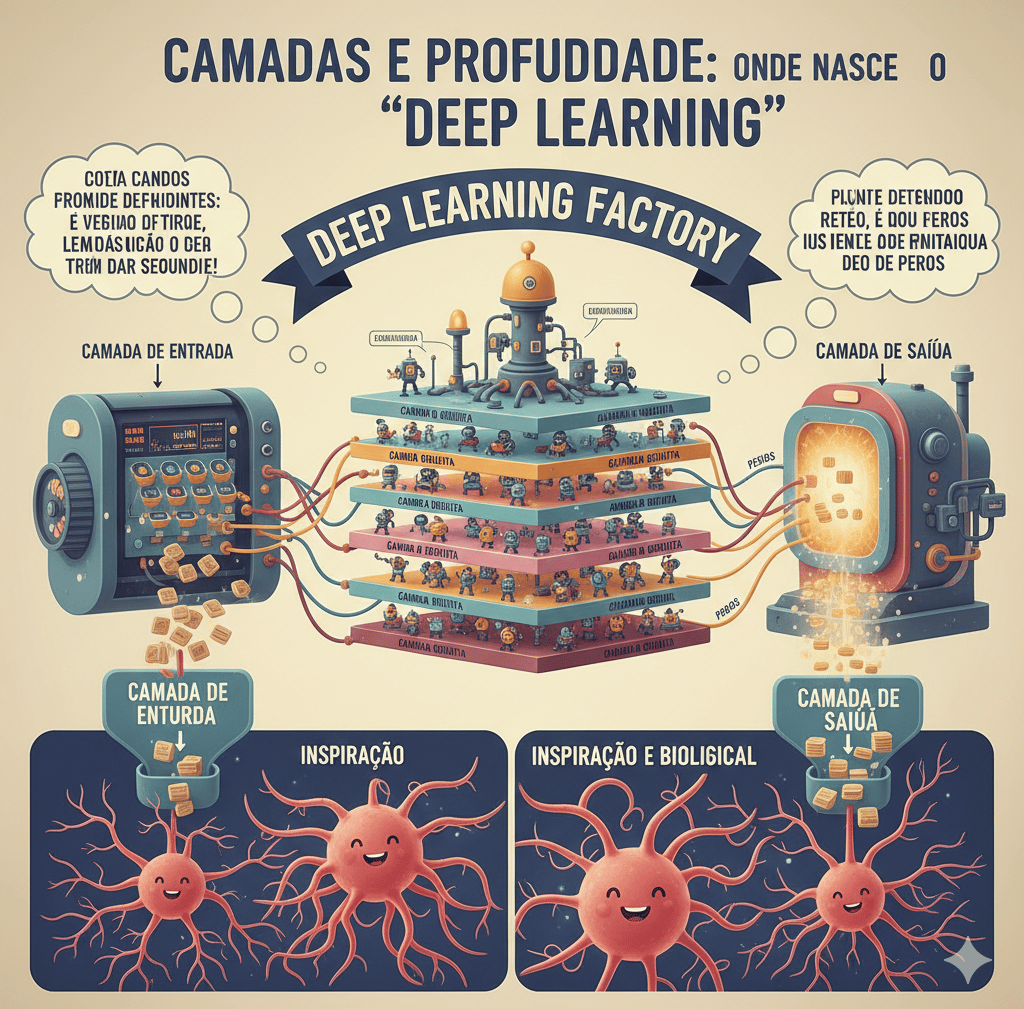
Já ouvimos o termo "Deep Learning" (Aprendizagem Profunda), mas o que é que isso significa realmente? No artigo anterior, vimos que uma rede neural tem neurónios conectados. Quando organizamos estes neurónios em muitas camadas, uma em cima da outra, criamos uma rede "profunda". A profundidade é o que permite à IA compreender conceitos complexos em vez de apenas dados brutos.
Numa rede neural típica, temos três tipos de camadas: a Camada de Entrada (Input), as Camadas Ocultas (Hidden Layers) e a Camada de Saída (Output). A camada de entrada é onde os dados entram (por exemplo, os pixéis de uma foto). A camada de saída é onde recebemos a resposta (por exemplo, "É um Gato"). O segredo da inteligência reside no que acontece nas camadas ocultas.
Imagine que a rede está a analisar a imagem de um rosto humano. Na primeira camada oculta, os neurónios estão apenas à procura de coisas simples: linhas verticais, horizontais ou curvas. Eles não sabem que estão a ver um rosto; apenas detetam bordas de luz e sombra. É o nível mais básico de perceção.
Na segunda camada, a rede pega nessas linhas e começa a combiná-las. Duas linhas curvas e um círculo podem formar o padrão de um "olho". Uma linha reta e duas curvas podem sugerir um "nariz". Nesta fase, a rede ainda não vê uma pessoa, mas já reconhece partes componentes de uma forma geométrica mais complexa.
À medida que subimos para a terceira, quarta ou centésima camada, os conceitos tornam-se cada vez mais abstratos. Uma camada profunda pode reconhecer expressões faciais, como "felicidade" ou "tristeza", baseando-se na posição relativa das partes detetadas nas camadas anteriores. A "profundidade" permite que a máquina construa uma hierarquia de conhecimento.
Para um leigo, pense nisto como um sistema de hierarquia numa empresa. Os estagiários (primeira camada) recolhem dados brutos. Os analistas (camadas intermédias) organizam esses dados em relatórios simples. Os diretores (camadas profundas) analisam os relatórios para tomar decisões estratégicas. Sem os níveis intermédios, o CEO não conseguiria compreender a confusão de dados que entra pela porta.
Para o iniciado, o Deep Learning resolve o problema da "extração de características". Antigamente, os engenheiros tinham de dizer à máquina o que procurar (características manuais). Com o Deep Learning, a própria rede descobre quais as características mais importantes através de uma técnica chamada descida de gradiente, otimizando a função de perda em milhares de dimensões simultaneamente.
A invenção que impulsionou o Deep Learning foi a utilização de GPUs (placas gráficas). Como as redes neurais são basicamente biliões de multiplicações de matrizes, o hardware desenhado para processar os gráficos de videojogos revelou-se perfeito para treinar estas IAs. O que demoraria anos num processador normal, passou a demorar dias ou horas.
No entanto, há um desafio: o problema da "Caixa Preta". À medida que as redes se tornam mais profundas e complexas, torna-se quase impossível para um ser humano explicar exatamente por que razão a IA tomou uma determinada decisão. Sabemos que ela funciona, mas rastrear o sinal através de 100 camadas de biliões de conexões é um desafio hercúleo para a transparência.
É esta arquitetura de camadas que permite que a IA faça coisas como tradução em tempo real. A rede não traduz palavra por palavra; ela processa a frase através de camadas que extraem o "significado" (semântica) da língua de origem e depois reconstrói esse significado na língua de destino.
A aprendizagem profunda é, portanto, a evolução da rede neural simples para um sistema de compreensão multinível. É o que permite passar da simples deteção de padrões para a compreensão de contextos, preparando o terreno para a revolução seguinte: a criação.


